Part 1
http://lwn.net/Articles/365835/
Part 2
http://lwn.net/Articles/366796/
Documentation/ftrace.txt
http://lwn.net/Articles/322731/
Thursday, December 24, 2009
Wednesday, July 22, 2009
在這裡,風很大、海很冷
這裡的風很大
味道是鹹的
是大海的氣息?!
還是海的眼淚?!
日子有時候就像大海
有時洶湧有時溫柔
身邊的風很大、海很冷,
而心卻有一個溫暖的港口
在這裡,風很大、海很冷,
請放心,我不會走遠的
就在這裡...等待夕陽下的海鷗歸巢
味道是鹹的
是大海的氣息?!
還是海的眼淚?!
日子有時候就像大海
有時洶湧有時溫柔
身邊的風很大、海很冷,
而心卻有一個溫暖的港口
在這裡,風很大、海很冷,
請放心,我不會走遠的
就在這裡...等待夕陽下的海鷗歸巢
Tuesday, April 07, 2009
Go back to basic
商業周刊/郭台銘:一手爛牌也要認真打!
更新日期:
2009/04/06 09:40文/鄭呈皇、林俊劭
三月二十九日青年節夜晚,台大藝文中心小教堂裡,有場與年輕學子的小型對談會。超過十年沒有現身校園演講的郭台銘,與七位高階主管現身,對談主題環繞著企業對新世代「人才」的需求。
歷經金融海嘯,大多數的企業選擇積極瘦身。但,郭台銘卻說,他更專注在人才投資上。「誰能夠吸引人才,給人才機會,這樣的企業在下一波景氣循環後,就是下一個贏家。」
滿手爛牌,不一定就會輸
他認為,在動盪的今日環境中,企業對人才的需求也在改變。
你就算有漂亮的學經歷條件,也不一定能找到好工作,「但,看來是滿手爛牌,也不一定會輸。」只要你願意改變既有的思維,隨時都會有翻身的機會。換個角度想,若你能沉著面對牌局,你已經先贏了一半。
以下,是郭台銘給大家三個在職場中「反敗為勝」的建議。
忘掉過去的經驗值
別再用過去的經驗法則,打這場牌局。「現在只有一件事情不會變,就是太陽從東邊出來!」郭台銘說。連花旗銀 行與AIG(美國國際集團)等大家認為永遠都不會倒的金融機構,都出現問題後,我們憑什麼相信,眼前的一切不會改變?郭台銘跟在場的年輕學子說,「回去, 告訴你們老師這件事情,把書架上的書,通通丟掉、拿去燒掉,那些理論所研究的案例,說穿了,都禁不起一場真正的(考驗)」「你說我要拿到一本秘笈(在天下 順利行走),這,是不可能的事情,」「基本的道理,一加一等於二,這個邏輯你把它記住就好,其他的東西,你都把它忘掉!」
不再迷信過去的理論,那,該怎麼做?
「Go back to basic(回到基本)你到少林寺去,先端水三年、蹲馬步三年,你沒有基礎,你不可能(做)成任何大事。」郭台銘建議,個人進入企業裡,都要有從頭開始學習、打長久戰的心理準備,不能再保持著不斷跳槽、打短線戰的心態。
要有憨勁,別當沙塔大象
鴻海集團副總經理戴家鵬補充,「就是喔,要有個『憨勁』,也就是要有個『傻勁』,不要太多小聰明。」「知道你未來五年後要做什麼、十年後要做什麼,你就往這方面,一步一步去努力。」
人要有憨勁,不要太計較,要讓自己像海綿般盡量吸收。就算財務人員,「我們都希望將來到現場去、到實務去,否則你沒有辦法曉得這間公司能不能投資,為什麼應收帳款高?為什麼獲利能夠成長?」郭台銘認為,企業未來需要的是,能知其然,也知其所以然的人才。
「十幾年前,我有機會去投資銀行,但沒有,因為我覺得銀行是在沙塔上面建立一個大象,隨時說倒就倒。」郭台銘說。同理,也可以用來檢視自己在職場的情境,你是行走上沙塔上的大象,還是,腳踏實地的憨人?這波海嘯,就可做最好的體檢。
走務實路線,執著下去
要成為一個傑出的人才。還有一件最重要的事,要選對方向,才「執著下去」。
「第一個十年,要務實一點,要為錢工作,不要太高調;第二個(階段)是為理想工作,第三個階段是為興趣而工作,」郭台銘說。若,今天你只是剛畢業的學子,要走務實路線,那麼,該怎麼挑工作?郭台銘還是那句老話:「拋掉過去的經驗值。」
走出慣性思考的範疇,去沉澱:哪個產業,最需要你的能耐?人的價值該值多少?該怎麼樣讓它升值?是不是擺在最合適的市場?郭台銘不僅提醒大家思考此議題,鴻海內部也開始與台大、政大合作,希望將人才的價值評估出來。
>>立即閱讀整本商周,請下載電子雜誌http://www.businessweekly.com.tw/adclick.php?id=2792
※ 精彩全文,詳見《商業周刊網站》。http://www.businessweekly.com.tw/※ 本文由商業周刊授權刊載,未經同意禁止轉載。
Monday, February 23, 2009
Stack Backtracing Inside Your Program
If you usually work with non-trivial C sources, you may have wondered which execution path (that is, which sequence of function calls) brought you to a certain point in your program. Also, it would be even more useful if you could have that piece of information whenever your beautiful, bug-free program suddenly crashes, and you have no debugger at hand. What is needed is a stack backtrace and, thanks to a little known feature of the GNU C library, obtaining it is a fairly easy task.
Before diving into the article, let's briefly go over how function calls and parameters pass work in C. In order to prepare for the function call, parameters are pushed on the stack in reverse order. Afterwards, the caller's return address also is pushed on the stack and the function is called. Finally, the called function's entry code creates some more space on the stack for storage of automatic variables. This layout commonly is called a stack frame for that particular instance of the function call. When more function calls are nested, the whole procedure is repeated, causing the stack to keep growing downwards and building a chain of stack frames (see Figure 1). Thus, at any given point in a program it theoretically is possible to backtrace the sequence of stack frames to the originating calling point, up to the main() function (to be exact, up to the libc function, which calls main() when the process starts up).
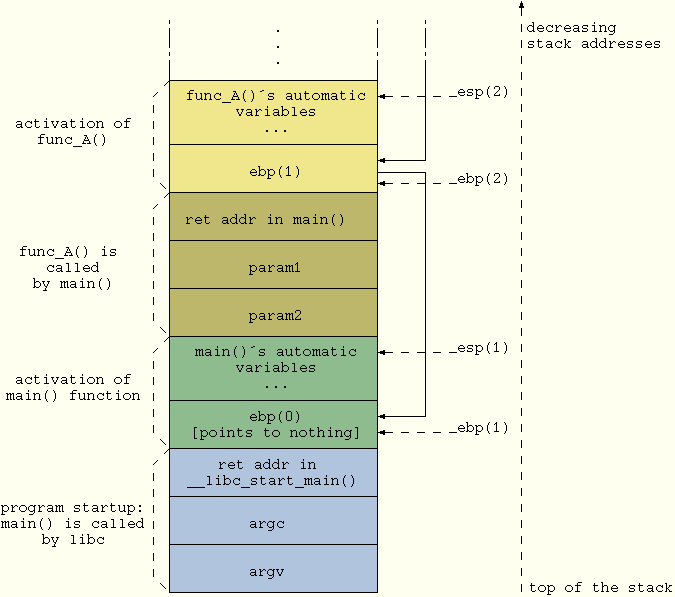
Figure 1. Nested Function Calls
Getting the stack backtrace with GDB (or an equivalent graphical front end) for a program that crashed while running is straightforward: you simply issue the bt command, which returns the list of functions called up to the point of the crash. As this is a standard practice, we do not provide any more details here; have a look at the GDB info page if you need specifics (info gdb stack gets you there).
If for some reason you're not running inside a debugger, two options are available for tracing what the program is doing. The first method is to disseminate it with print and log messages in order to pinpoint the execution path. In a complex program, this option can become cumbersome and tedious even if, with the help of some GCC-specific macros, it can be simplified a bit. Consider, for example, a debug macro such as
#define TRACE_MSG fprintf(stderr, __FUNCTION__ \
"() [%s:%d] here I am\n", \
__FILE__, __LINE__)
You can propagate this macro quickly throughout your program by cutting and pasting it. When you do not need it anymore, switch it off simply by defining it to no-op.
A nicer way to get a stack backtrace, however, is to use some of the specific support functions provided by glibc. The key one is backtrace(), which navigates the stack frames from the calling point to the beginning of the program and provides an array of return addresses. You then can map each address to the body of a particular function in your code by having a look at the object file with the nm command. Or, you can do it a simpler way--use backtrace_symbols(). This function transforms a list of return addresses, as returned by backtrace(), into a list of strings, each containing the function name offset within the function and the return address. The list of strings is allocated from your heap space (as if you called malloc()), so you should free() it as soon as you are done with it.
If you prefer to avoid dynamic memory allocation during the backtrace--reasonable, as the backtrace is likely to happen under faulty conditions--you can resort to backtrace_symbols_fd(). This prints the strings directly to the given file descriptor and does not allocate new memory for strings storage. It is a safer choice in those cases where memory heap potentially is corrupted.
In order to convert an address to a function name, the last two functions rely on symbol information to be available inside the program itself. To enable this feature, compile your program with the -rdynamic option (see man dlopen for more details).
Listing 1. How to Use the Backtrace Functions
Listing 1 demonstrates how to use these functions. The test() function calls either func_low() or func_high(), both of which call show_stackframe() to print out the execution path. The program is compiled with
gcc -rdynamic listing1.c -o listing1
The output should look something like:
Execution path:
./listing1(show_stackframe+0x2e) [0x80486de]
./listing1(func_high+0x11) [0x8048799]
./listing1(test+0x43) [0x80487eb]
./listing1(main+0x13) [0x8048817]
/lib/libc.so.6(__libc_start_main+0xbd) [0x4003e17d]
./listing1(backtrace_symbols+0x31) [0x80485f1]
First call: 167
Execution path:
./listing1(show_stackframe+0x2e) [0x80486de]
./listing1(func_low+0x11) [0x8048779]
./listing1(test+0x21) [0x80487c9]
./listing1(main+0x33) [0x8048837]
/lib/libc.so.6(__libc_start_main+0xbd) [0x4003e17d]
./listing1(backtrace_symbols+0x31) [0x80485f1]
Second call: -3
By the way, function prototypes for the backtrace functions reside in the header file execinfo.h.
At this point, we have in hand a tool that is able to print the list of function calls up to the current execution point. This can be a useful tool in many different contexts. Think of having a complex program and needing to know who's calling a given function with the wrong parameters. With a simple check and a call to our show_stackframe() function, the faulty caller can be spotted easily.
An even more useful application for this technique is putting a stack backtrace inside a signal handler and having the latter catch all the "bad" signals your program can receive (SIGSEGV, SIGBUS, SIGILL, SIGFPE and the like). This way, if your program unfortunately crashes and you were not running it with a debugger, you can get a stack trace and know where the fault happened. This technique also can be used to understand where your program is looping in case it stops responding. All you need to do is set up a SIGUSR1/2 handler and send such a signal when needed. Before presenting an example, we need to open a parenthesis on signal handling.
Backtracing from within a signal handler requires some interesting intricacies that take us on a little detour through signal delivery to processes. Going into deep detail on this matter is outside the scope of this article, but we briefly can summarize it this way:
When the kernel needs to notify a signal of a given process, it prepares some data structures attached to the process' task struct and sets a signal-pending bit.
Later on, when the signalee process is scheduled for execution, its stack frame is altered by the kernel in order to have EIP point to the process' signal handler. This way, when the process runs it behaves as if it had called its own signal handler by itself before being suspended.
The initial steps of user space signal management are taken care of inside libc, which eventually calls the real process' signal handling routines which, in turn, execute our stack backtrace function.
As a consequence of this mechanism, the first two entries in the stack frame chain when you get into the signal handler contain, respectively, a return address inside your signal handler and one inside sigaction() in libc. The stack frame of the last function called before the signal (which, in case of fault signals, also is the one that supposedly caused the problem) is lost. Thus, if function B called function A, which in turn caused a SIGSEGV, a plain backtrace would list these entry points:
your_sig_handler()
sigaction() in libc.so
func_B()
main()
and no trace of the call to function A would be found. For more details, have a look at the manuals for signal() and sigaction().
In order to get a meaningful backtrace, we need a workaround. Luckily, when you have the sources of both the kernel and libc, you can find a workaround for nearly anything. In Listing 2 we exploit an undocumented parameter of type sigcontext that is passed to the signal handler (see the UNDOCUMENTED section in man sigaction) and contains, among other things, the value of EIP when the signal was raised. After the call to backtrace(), we use this value to overwrite the useless entry corresponding to the sigaction() return address in the trace array. When we later call backtrace_symbols(), the address we inserted is resolved the same as any other entry in the array. Finally, when we print the backtrace, we start from the second entry (i=1 in the loop), because the first one always would be inside our signal handler.
Since kernel version 2.2 the undocumented parameter to the signal handler has been declared obsolete in adherence with POSIX.1b. A more correct way to retrieve additional information is to use the SA_SIGINFO option when setting the handler, as shown in Listing 3 and documented in the man page. Unfortunately, the siginfo_t structure provided to the handler does not contain the EIP value we need, so we are forced to resort again to an undocumented feature: the third parameter to the signal handler. No man page is going to tell you that such a parameter points to an ucontext_t structure that contains the values of the CPU registers when the signal was raised. From this structure, we are able to extract the value of EIP and proceed as in the previous case.
A couple of points are important to keep in mind when you use the backtrace functions. First, backtrace_symbols() internally calls malloc() and, thus, can fail if the memory heap is corrupted--which might be the case if you are dealing with a fault signal handler. If you need to resolve the return addresses in such a situation, calling backtrace_symbols_fd() is safer, because it directly writes to the given file descriptor without allocating memory. The same reasoning implies that it is safer to use either static or automatic (non dynamic) storage space for the array passed to backtrace().
Also, there are some limitations to the ability of automatically tracing back the execution of a program. The most relevant are some compiler optimizations that, in one way or another, alter the contents of the stack frame or even prevent a function from having one (think of function inlining). Obviously, the stack frame does not even exist for macros, which are not function calls at all. Finally, a stack backtrace is impossible to perform if the stack itself has been corrupted by a memory trash.
Regarding symbol resolution, the current glibc (version 2.3.1 at the time of this writing) allows users to obtain the function name and offset only on systems based on the ELF binary format. Furthermore, static symbols' names cannot be resolved internally, because they cannot be accessed by the dynamic linking facilities. In this case, the external command addr2line can be used instead.
In case you wonder how would you access stack information in a C program, the answer is simple: you can't. Stack handling, in fact, depends heavily on the platform your program runs on, and the C language does not provide any means to do it in a standard way. The implementation of backtrace() in the glibc library contains platform-specific code for each platform, which is based either on GCC internal variables (__builtin_frame_address and __builtin_return_address) or on assembly code.
In the case of the i386 platform (in glibc-x.x.x/sysdeps/i386/backtrace.c), a couple of lines of assembly code are used to access the contents of the ebp and esp CPU registers, which hold the address of the current stack frame and of the stack pointer for any given function:
register void *ebp __asm__ ("ebp");
register void *esp __asm__ ("esp");
Starting from the value of ebp, it is easy to follow the chain of pointers and move up to the initial stack frame. In this way you gather the sequence of return addresses and build the backtrace.
At this point, you still have to resolve the return addresses into function names, an operation dependent on the binary format you are using. In the case of ELF, it is performed by using a dynamic linker internal function (_dl_addr(), see glibc-x.x.x/sysdeps/generic/elf/backtracesyms.c).
Are you working on a complex program that contains a lot of different execution paths that make you cluelessly wander through hundreds of functions, desperately trying to understand which one called which other function? Wander no more and print a backtrace. It's free, fast and easy. While you are at it, do yourself a favour and also use that function inside a fault signal handler--it's guaranteed to help you with those nasty bugs that appear once in a thousand runs.
Gianluca Insolvibile has been a Linux enthusiast since kernel 0.99pl4. He currently deals with networking and digital video research and development.

Resources for Tracing Linux
Unix下工具
grep: “grep [option] …pattern… [file] ”
ex : grep –ri return rtlcore.c
無敵的指令,雖然可能找很久
ctags: “find -name ‘*.[ch]’ | xargs ctags”
這樣檔案tags裡就有各種關鍵字的索引了
cflow: “cflow –r fun_name *.c”
產生call graph
c2html: “c2html <> file.html”
結構圖繪制工具
Jude
http://objectclub.esm.co.jp/Jude/
grep: “grep [option] …pattern… [file] ”
ex : grep –ri return rtlcore.c
無敵的指令,雖然可能找很久
ctags: “find -name ‘*.[ch]’ | xargs ctags”
這樣檔案tags裡就有各種關鍵字的索引了
cflow: “cflow –r fun_name *.c”
產生call graph
c2html: “c2html <> file.html”
結構圖繪制工具
Jude
http://objectclub.esm.co.jp/Jude/
Sunday, February 22, 2009
耶和華所賜的福使人富足,並不加上憂愁。
耶和華所賜的福使人富足,並不加上憂愁。(箴言10:22)
The blessing of the LORD brings wealth,
and he adds no trouble to it. (Proverbs 10:22)
The blessing of the LORD brings wealth,
and he adds no trouble to it. (Proverbs 10:22)
Saturday, February 07, 2009
x86 32bit call backtrace
需include
driver可以用dump_stack() 這個func來back trace
不過還沒有試過,能不能work還未知
底下是x86 32bit的實作
driver可以用dump_stack() 這個func來back trace
不過還沒有試過,能不能work還未知
底下是x86 32bit的實作
http://lxr.linux.no/linux+v2.6.27.2/arch/x86/kernel/traps_32.c#L288288void dump_stack(void)
289{
290 unsigned long bp = 0;
291 unsigned long stack;
292
293#ifdef CONFIG_FRAME_POINTER
294 if (!bp)
295 asm("movl %%ebp, %0" : "=r" (bp):);
296#endif
297
298 printk("Pid: %d, comm: %.20s %s %s %.*s\n",
299 current->pid, current->comm, print_tainted(),
300 init_utsname()->release,
301 (int)strcspn(init_utsname()->version, " "),
302 init_utsname()->version);
303
304 show_trace(current, NULL, &stack, bp);
305}
306
307EXPORT_SYMBOL(dump_stack);
Thursday, February 05, 2009
x86 32bit call backtrace
http://lxr.linux.no/linux+v2.6.27.2/arch/x86/kernel/traps_32.c#L309
329 printk("\n" KERN_EMERG "Stack: ");
330 show_stack_log_lvl(NULL, regs, ®s->sp, 0, KERN_EMERG);
331
332 printk(KERN_EMERG "Code: ");
330行是show call backtrace func的實作
Wednesday, February 04, 2009
Enable Backtrace
Enable Backtrace
April 18th, 2007 · 3 Comments
最近 Linux kernel 2.4 的 Backtrace 不見了, 這樣實在非常不好 Debug,
查了一下才發現, 少加了一些 Flags.
原來會顯示(部份)
Process swapper (pid: 1, stack limit = 0xc030a368)
Stack: (0xc030bfc0 to 0xc030c000)
bfc0: c0042410 c00424a8 c030a000 c020f558 c0011118 c030a000 c020f558 c0200d10
bfe0: 000191cc c00430d8 c00430a4 c01fe000 c0237948 c0046974 c4a57686 1b469a8c
Backtrace: no frame pointer
Code: c0237ba0 e92d40f0 e3a04000 e1a05004 (e5854000)
Kernel panic: Attempted to kill init!
這時是沒有 frame pointer , 這時在 compile 時加上參數 -fomit-frame-pointer
就可以了. 以 Linux 2.4 ARM Platform 為例, 請在 arch/arm/Makefile 的 cflags 加上
這個參數
加了以後, 程式有問題就會顯示
Process swapper (pid: 1, stack limit = 0xc0efa368)
Stack: (0xc0efbf9c to 0xc0efc000)
bf80: c0042a70
bfa0: c0042b08 c0efa000 c0217558 c0efbfd8 c0efbfbc c00114cc c0011820 c0efa000
bfc0: c0217558 c0208d10 00019834 c0efbff4 c0efbfdc c00430e0 c00114c8 c00430a4
bfe0: c0206000 c023f948 00000000 c0efbff8 c0046a54 c00430b4 00000000 00000000
Backtrace:
Function entered at [] from [ ]
r7 = C0217558 r6 = C0EFA000 r5 = C0042B08 r4 = C0042A70
Function entered at [] from [ ]
Function entered at [] from [ ]
r6 = C023F948 r5 = C0206000 r4 = C00430A4
Code: e92dd8f0 e24cb004 e3a04000 e1a05004 (e5854000)
Kernel panic: Attempted to kill init!
但是這一堆 Code, 實在是看不懂, 那要怎麼辦呢? 還好 Linux kernel 2.4 有提供一個
Tool: ksymoops 可以用.
執行指令
ksymoops -m System.map
將 Backtrace 那一段貼上去
Backtrace:
Function entered at [] from [ ]
r7 = C0217558 r6 = C0EFA000 r5 = C0042B08 r4 = C0042A70
Function entered at [] from [ ]
Function entered at [] from [ ]
r6 = C023F948 r5 = C0206000 r4 = C00430A4
Code: e92dd8f0 e24cb004 e3a04000 e1a05004 (e5854000)
Kernel panic: Attempted to kill init!
Backtrace:
Function entered at [] from [ ]
r7 = C0217558 r6 = C0EFA000 r5 = C0042B08 r4 = C0042A70
Function entered at [] from [ ]
Function entered at [] from [ ]
r6 = C023F948 r5 = C0206000 r4 = C00430A4
Code: e92dd8f0 e24cb004 e3a04000 e1a05004 (e5854000)
就會得到結果
Trace; c0011810 <$a+0/0>
Trace; c00114cc>>r7; c0217558 <__machine_arch_type+0/4>
>>r5; c0042b08 <__initcall_end+0/4f8>
>>r4; c0042a70 <$d+0/0>Trace; c00114b8 <$a+0/0>
Trace; c00430e0
Trace; c00430a4
Trace; c0046a54>>r6; c023f948
>>r5; c0206000
>>r4; c00430a4Code; c0011814
00000000 <_eip>:
Code; c0011814
0: f0 d8 2d e9 04 b0 4c lock fsubrs 0×4cb004e9
Code; c001181b
7: e2 00 loop 9 <_eip+0×9>
Code; c001181d
9: 40 inc %eax
Code; c001181e
a: a0 e3 04 50 a0 mov 0xa05004e3,%al
Code; c0011823
f: e1 00 loope 11 <_eip+0×11>
Code; c0011825
11: 40 inc %eax
Code; c0011826
12: 85 e5 test %esp,%ebpKernel panic: Attempted to kill init!
這樣就可以清楚的知道, 到底是那邊發生問題了.
Linux kernel 2.6 己經內建在 Option 內了, 在 Option “[ ] Configure standard kernel features (for small systems) “, Enable 後就看得到了.
雖然是小問題, 不過也是要找一下的.
ref.
Jserv GCC 函式追蹤功能
Linux Device Driver 3 Chapter 4. Debugging Techniques
[Tags] Linux kernel, Debug [/Tags]
做出自己的back trace function
相信有在用arm linux的, 應該對kernel panic不陌生吧~~ 在你對kernel做了一些無法挽救的錯事後, kernel叫了一聲"Oops~~",然後就死在路邊~~ 不過幸運的事, 通常kernel會在死之前留下一些"線索", 好讓你跟隨這些線索找出些端倪...
舉例來說, 我故意在我的init module 裡插入存取非法位址的動作, kernel果然就掛在那邊並且印出:
Unable to handle kernel paging request at virtual address dcc01120
pgd = c0004000
[dcc01120] *pgd=00000000
Internal error: Oops: 805 [#1]
Modules linked in:
CPU: 0
PC is at audio_aic32_init+0x44/0x1cc
LR is at 0x1
pc : [] lr : [<00000001>] Not tainted
sp : c0387fc4 ip : 60000013 fp : c0387fd4
r10: 00000000 r9 : 00000000 r8 : 00000000
r7 : c001f70c r6 : 00000000 r5 : c0386000 r4 : 00000000
r3 : fbbc0000 r2 : e1041128 r1 : 00000001 r0 : e1041120
Flags: nZCv IRQs on FIQs on Mode SVC_32 Segment kernel
Control: 5317F Table: 80004000 DAC: 00000017
Process swapper (pid: 1, stack limit = 0xc0386198)
Stack: (0xc0387fc4 to 0xc0388000)
7fc0: c001f6dc c0387ff4 c0387fd8 c0076290 c001d00c 00000000 00000000
7fe0: 00000000 00000000 00000000 c0387ff8 c008d738 c007620c 00000000 00000000
Backtrace:
[] (audio_aic32_init+0x0/0x1cc) from [] (init+0x94/0x1e0)
r4 = C001F6DC
[] (init+0x0/0x1e0) from [] (do_exit+0x0/0xdc0)
r7 = 00000000 r6 = 00000000 r5 = 00000000 r4 = 00000000
Code: e59f3174 e3a01001 e5801000 e2422d25 (e7801003)
<0>Kernel panic - not syncing: Attempted to kill init!
嘿嘿, 很明顯的kernel就是死在audio_aic32_init,
我們再去仔細看看這個function即可;
這麼說起來, kernel的這個機制還真好用, 能讓我們了解掛掉的時候,
是由哪幾個function call下來的,
那麼...我們有沒有辦法拿來用呢?
有時你會想知道, kernel到底何時, 又是從哪呼叫到這個function;
又有時你會想知道, kernel到底怎麼call到我們function裡的,
我明明只是在結構中加入 .probe= probe_function,
kernel卻能找到我的probe_function, 到底是從哪進入的呢,
當然你也可以一層一行的去追code去printk,
但是如果能善用kernel的這個"線索"function, 想必能省力不少
好, 既然要用這個工具,
讓我們先找看看他被放在kernel source tree的哪裡
用lxr search看看, 發現他是位於/arch/arm/kernel/traps.c
從die開始(但是如何跑到die的呢? 我猜是fault interrupt),接著die()->dump_backtrace()->c_backtrace(),
但是lxr search不到c_backtrace不到, 按照慣例,
應該是一個assembly functon,
去arch/arm/lib/裡找找, 果然找到一個backtrace.S,
c_backtrace就在裡面,
有興趣的可以去看看他是怎麼寫的, 我則只想知道怎麼用它
最簡單的方式就是 看dump_backtrace()是怎麼call c_backtrace()的, 我們跟著做, 這樣應該就能印出資訊吧
在dump_backtrace()裡:
157 static void dump_backtrace(struct pt_regs *regs, struct task_struct *tsk)
158 {
159 unsigned int fp;
160 int ok = 1;
161
162 printk("Backtrace: ");
163 fp = regs->ARM_fp;
164 if (!fp) {
165 printk("no frame pointer");
166 ok = 0;
167 } else if (verify_stack(fp)) {
168 printk("invalid frame pointer 0x%08x", fp);
169 ok = 0;
170 } else if (fp < (unsigned long)(tsk->thread_info + 1))
171 printk("frame pointer underflow");
172 printk("\n");
173
174 if (ok)
175 c_backtrace(fp, processor_mode(regs));
176 }
其中 c_backtrace需要2個參數, 一個是fp,
一個是processor目前的mode
processor 目前的mode倒是比較容易解決,
因為我們driver都是在system mode, 所以傳入固定0x1f即可
至於fp呢, 要取得就比較麻煩啦, 要先get register的值, 我的做法如下
static void load_regs( struct pt_regs *ptr )
{
asm volatile(
"stmia %0, {r0 - r15}\n\t"
:
: "r" (ptr)
: "memory"
);
}
最後則是寫成一個function 讓別人call啦~
void back_trace( void )
{
struct pt_regs *ptr;
unsigned int fp;
unsigned long flags;
ptr = kmalloc( sizeof( struct pt_regs ), GFP_KERNEL);
local_irq_save(flags);
printk("\n\nstart back trace...");
load_regs( ptr );
fp = ptr->ARM_fp;
c_backtrace(fp, SYS_MODE);
printk("back trace end...\n\n");
local_irq_restore(flags);
kfree ( ptr );
}
EXPORT_SYMBOL( back_trace);
如此, 我們只要在driver中加入back_trace();
就可以知道整個來龍去脈啦
舉個例子, 在audio 的probe function中加入back_trace();
則會印出start back trace...
[] (back_trace+0x0/0x68) from [] (davinci_aic32_probe+0x3c/0x144)
r5 = C0293EE8 r4 = 00000000
[] (davinci_aic32_probe+0x0/0x144) from [] (audio_probe+0x24/0x2c)
r5 = C02471B4 r4 = C024725C
[] (audio_probe+0x0/0x2c) from [] (driver_probe_device+0x54/0x74)
[] (driver_probe_device+0x0/0x74) from [] (driver_attach+0x54/0x90)
r5 = C024725C r4 = C02471BC
[] (driver_attach+0x0/0x90) from [] (bus_add_driver+0x78/0x120)
r6 = C024725C r5 = C0293E48 r4 = C0243C34
[] (bus_add_driver+0x0/0x120) from [] (audio_register_codec+0xbc/0xe8)
[] (audio_register_codec+0x0/0xe8) from [] (audio_aic32_init+0x14/0x1c4)
r6 = 00000000 r5 = C0386000 r4 = C001F6DC
[] (audio_aic32_init+0x0/0x1c4) from [] (init+0x94/0x1e0)
r4 = C001F6DC
[] (init+0x0/0x1e0) from [] (do_exit+0x0/0xdc0)
r7 = 00000000 r6 = 00000000 r5 = 00000000 r4 = 00000000
back trace end...
如此,整個流程就清清楚楚了~~~
linux kernel source code
一個source code分析與討論的好網站
http://linux.chinaunix.net/bbs/forum-8-1.html
已完成--基于LINUX内核中的TCP/IP的核心过程分析
http://linux.chinaunix.net/bbs/thread-1049757-1-2.html
如何阅读内核网络部分的代码?
http://linux.chinaunix.net/bbs/thread-1058937-1-2.html
TCP协议内核源码分析第一册v1.0.chm (671.73 KB)
http://linux.chinaunix.net/bbs/thread-1054108-1-5.html
网卡驱动注册到PCI总线这一过程的分析
http://linux.chinaunix.net/bbs/thread-1052717-1-4.html
个人对kobject的一点研究
http://linux.chinaunix.net/bbs/thread-1058833-1-2.html
http://linux.chinaunix.net/bbs/forum-8-1.html
已完成--基于LINUX内核中的TCP/IP的核心过程分析
http://linux.chinaunix.net/bbs/thread-1049757-1-2.html
如何阅读内核网络部分的代码?
http://linux.chinaunix.net/bbs/thread-1058937-1-2.html
TCP协议内核源码分析第一册v1.0.chm (671.73 KB)
http://linux.chinaunix.net/bbs/thread-1054108-1-5.html
网卡驱动注册到PCI总线这一过程的分析
http://linux.chinaunix.net/bbs/thread-1052717-1-4.html
个人对kobject的一点研究
http://linux.chinaunix.net/bbs/thread-1058833-1-2.html
Saturday, January 10, 2009
RT PREEMPT HOWTO
RT PREEMPT HOWTO
http://rt.wiki.kernel.org/index.php/RT_PREEMPT_HOWTO#About_the_RT-Preempt_Patchhttp://www.osadl.org/Realtime-Preempt-Kernel.kernel-rt.0.html
realtime Preempt Patch wiki
Friday, January 09, 2009
Linux Real Time Patch Review - Vanilla vs. RT patch comparison
Linux Real Time Patch Review - Vanilla vs. RT patch comparison
Hardly any standard operating system kernel is hard real time capable. At best, they're soft real time capable, with latencies up to milliseconds.
RTAI and Xenomai provide hard real time, which means that those operating systems (inserted between the hardware and Linux) can assure interrupt response times in the microsecond range. Not so with that standard Linux kernel. The 2.6 kernel - in comparison to the 2.4 kernel - has been much improved in regard to latencies, but still has some bottlenecks. Ingo Molnar provides a patch to compensate for those bottlenecks.
Ingo Molnar RealTime Preempt Patch
This patch improves the responsiveness of the kernel dramatically.
The tests below have been conducted with a tool provided by Andrew Morton. Within the amlat package, there is a tool called "realfeel" which also works on 2.6 kernels, despite the "amlat" tool which, well, doesn't even work on 2.4 kernels on recent systems.
Linux scheduling latency (Andrew Morton)
Here is a small tar.gz which provides just the "realfeel" tool from the AKPM package and the famous "hackbench" (tweaked to acually compile):
captest.tar.gz (2k)
Compile with "make".
If you get something like this with "realfeel":
In any case, you should unload the module "genrtc" and load the module "rtc".
THE RESULTS
The result with a vanilla 2.6.15 kernel:
(first column is in milliseconds; second column is the number of RTC (real time clock) interrupts received)
Results with the rt16 RT patch:
If there is no or almost no load on your system, take into account that SMI (System Maintenance Interrupts on e.g. Intel 82845 845 (Brookdale) motherboards) can and will produce latencies of > 200us. Also see: Xenomai: High latencies with SMI not disabled
CONCLUSIONS:
If you need to have a low latency system for audio, music or video processing, the Molnar low latency patch might be the right thing for you.
But still, if you need hard real time performance, where latencies must not be higher than a few tens of microseconds, you'll better off with RTAI or XENOMAI.
Appendix:
Here are a few stress testing routines proven to be good for determining the worst case latencies.
If you want to combine some of those:
If you use "hackbench" you can try this:
Most hardcore test
Philippe Gerum (Ingo Molnar):
http://lkml.org/lkml/2005/6/22/347
And last but not least, here is a process listing of the processes on a RT preempt patch patched kernel and a vanilla kernel just after booting on a debian sarge system ...
... to illustrate the differences between the rt-patch and vanilla kernel system:
2.6.15-rt16
2.6.15 vanilla
Last-Modified: Thu, 09 Feb 2006 19:14:41 GMT
Hardly any standard operating system kernel is hard real time capable. At best, they're soft real time capable, with latencies up to milliseconds.
RTAI and Xenomai provide hard real time, which means that those operating systems (inserted between the hardware and Linux) can assure interrupt response times in the microsecond range. Not so with that standard Linux kernel. The 2.6 kernel - in comparison to the 2.4 kernel - has been much improved in regard to latencies, but still has some bottlenecks. Ingo Molnar provides a patch to compensate for those bottlenecks.
Ingo Molnar RealTime Preempt Patch
This patch improves the responsiveness of the kernel dramatically.
The tests below have been conducted with a tool provided by Andrew Morton. Within the amlat package, there is a tool called "realfeel" which also works on 2.6 kernels, despite the "amlat" tool which, well, doesn't even work on 2.4 kernels on recent systems.
Linux scheduling latency (Andrew Morton)
Here is a small tar.gz which provides just the "realfeel" tool from the AKPM package and the famous "hackbench" (tweaked to acually compile):
captest.tar.gz (2k)
Compile with "make".
For the hackbench stress test call it like this:# ./realfeel histogramfilename.hist
1400.038 MHz
secondsPerTick=0.000000
ticksPerSecond=1400037759.748198
2048 Hz
0.451 msec
0.361 msec
-0.004 msec
-0.029 msec
-0.146 msec
-0.205 msec
Adjust the parameter - WARNING: if the parameter is too high, your system might freeze!# ./hackbench 100
If you get something like this with "realfeel":
do this:ioctl(RTC_IRQP_SET) failed: Invalid argument
This removes the module "genrtc" and loads the "rtc" (real time clock driver).# rmmod genrtc
# modprobe rtc
In any case, you should unload the module "genrtc" and load the module "rtc".
THE RESULTS
The result with a vanilla 2.6.15 kernel:
(first column is in milliseconds; second column is the number of RTC (real time clock) interrupts received)
0.0 54410As you can see, the max. latency of the RTC interrupt was about 3.7 milliseconds. (UPDATE: with "hackbench" I've even got more than ONE SECOND!!!)
0.1 32
0.2 8
0.3 5
0.4 3
0.5 1
0.6 1
0.8 1
1.0 1
1.4 1
1.5 1
2.0 1
3.7 1
Results with the rt16 RT patch:
0.0 308821As you can see, the max. latency was just about 200 microseconds. (UPDATE: with "hackbench" I got a max. of about 400us)
0.1 832
0.2 104
If there is no or almost no load on your system, take into account that SMI (System Maintenance Interrupts on e.g. Intel 82845 845 (Brookdale) motherboards) can and will produce latencies of > 200us. Also see: Xenomai: High latencies with SMI not disabled
CONCLUSIONS:
If you need to have a low latency system for audio, music or video processing, the Molnar low latency patch might be the right thing for you.
But still, if you need hard real time performance, where latencies must not be higher than a few tens of microseconds, you'll better off with RTAI or XENOMAI.
Appendix:
Here are a few stress testing routines proven to be good for determining the worst case latencies.
# dd if=/dev/zero of=bigfile bs=1024000 count=1024
# ping -l 100000 -q -s 10 -f localhost
# ping -f -s 1400 & dd if=/dev/urandom of=/dev/null & ls -lR /
# - a=0; while "true"; do cat /proc/interrupts; a=`expr $a + 1`; echo $a; done
# while :; do dd if=/dev/zero of=/tmp/foo bs=1M count=500; sync; rm /tmp/foo; done
If you want to combine some of those:
#!/bin/sh-or one from Paolo Mantegazza (RTAI.org)
dd if=/dev/zero of=bigfile1 bs=1024000 count=1000 &
ping -l 100000 -q -s 10 -f localhost &
du / &
a=0; while "true"; do dd if=/dev/hda1 of=/dev/null bs=1M count=1000;(this is just one line!)
a=`expr $a + 1`; date; echo $a; done
If you use "hackbench" you can try this:
#!/bin/sh
while true; do dd if=/dev/zero of=bigfile bs=1024000 count=1024; done &
while true; do killall hackbench; sleep 5; done &
while true; do ./hackbench 20; done &
ping -l 100000 -q -s 10 -f localhost &
du / &
Most hardcore test
Philippe Gerum (Ingo Molnar):
http://lkml.org/lkml/2005/6/22/347
while true; do dd if=/dev/zero of=bigfile bs=1024000 count=1024; done &
while true; do killall hackbench; sleep 5; done &
while true; do ./hackbench 20; done &
( cd ltp-full-20040707; while true; do ./runalltests.sh -x 40; done; ) &
ping -l 100000 -q -s 10 -f localhost &
du / &
And last but not least, here is a process listing of the processes on a RT preempt patch patched kernel and a vanilla kernel just after booting on a debian sarge system ...
... to illustrate the differences between the rt-patch and vanilla kernel system:
2.6.15-rt16
# ps -A
PID TTY TIME CMD
1 ? 00:00:00 init
2 ? 00:00:00 softirq-high/0
3 ? 00:00:00 softirq-timer/0
4 ? 00:00:00 softirq-net-tx/
5 ? 00:00:00 softirq-net-rx/
6 ? 00:00:00 softirq-scsi/0
7 ? 00:00:00 softirq-tasklet
8 ? 00:00:00 desched/0
9 ? 00:00:03 events/0
10 ? 00:00:00 khelper
11 ? 00:00:00 kthread
12 ? 00:00:00 kblockd/0
13 ? 00:00:00 pdflush
14 ? 00:00:00 pdflush
16 ? 00:00:00 aio/0
15 ? 00:00:00 kswapd0
17 ? 00:00:00 kseriod
18 ? 00:00:00 IRQ 12
19 ? 00:00:00 IRQ 14
20 ? 00:00:00 kjournald
21 ? 00:00:00 IRQ 1
378 ? 00:00:00 IRQ 19
389 ? 00:00:00 IRQ 4
392 ? 00:00:00 IRQ 3
544 ? 00:00:00 syslogd
547 ? 00:00:00 klogd
579 ? 00:00:00 exim4
584 ? 00:00:00 inetd
592 ? 00:00:00 sshd
597 ? 00:00:00 atd
600 ? 00:00:00 cron
606 tty1 00:00:00 getty
607 tty2 00:00:00 getty
608 tty3 00:00:00 getty
609 tty4 00:00:00 getty
610 tty5 00:00:00 getty
611 tty6 00:00:00 getty
612 ? 00:00:00 sshd
614 pts/0 00:00:00 bash
618 pts/0 00:00:00 ps
2.6.15 vanilla
# ps -A
PID TTY TIME CMD
1 ? 00:00:00 init
2 ? 00:00:00 ksoftirqd/0
3 ? 00:00:04 events/0
4 ? 00:00:00 khelper
5 ? 00:00:00 kthread
6 ? 00:00:00 kblockd/0
7 ? 00:00:00 pdflush
8 ? 00:00:00 pdflush
10 ? 00:00:00 aio/0
9 ? 00:00:00 kswapd0
11 ? 00:00:00 kseriod
12 ? 00:00:00 kjournald
532 ? 00:00:00 syslogd
535 ? 00:00:00 klogd
567 ? 00:00:00 exim4
572 ? 00:00:00 inetd
580 ? 00:00:00 sshd
585 ? 00:00:00 atd
588 ? 00:00:00 cron
594 tty1 00:00:00 getty
595 tty2 00:00:00 getty
596 tty3 00:00:00 getty
597 tty4 00:00:00 getty
598 tty5 00:00:00 getty
599 tty6 00:00:00 getty
602 ? 00:00:00 sshd
604 pts/0 00:00:00 bash
609 pts/0 00:00:00 ps
Last-Modified: Thu, 09 Feb 2006 19:14:41 GMT
Linus Torvalds on git
轉自 http://people.debian.org.tw/~chihchun/2008/12/19/linus-torvalds-on-git/
Linus Torvalds on git
這段錄影已經躺在硬碟中很久,這兩日才利用通勤的時間消化了一番。這是 Linus Torvalds 在 Google 所進行的一段演講,身為一個性格強硬的硬底子駭客,他時常發出驚人的評論,有些有趣的言論甚至被整理成格言集,像是 The 10 Best Linus Torvalds Quotes 或 Linus Torvalds Quotes。
在這段演講中,身為 Git 計畫的發起人,Linus 說明了為什麼需要設計這樣的一套工具,基本的設計哲學與其他類似的工具的比較。
在技術的觀點上,他直接且尖銳的同時批判了 CVS 與 Subversion, 演講一開始 Linus 就給了 CVS 贊頌 - 負面的贊頌,雖然 Linus 從來不用 CVS 管理 Kernel source tree,但是還是在商業公司有過一段不短時間的使用經驗,而且 Linus 打從心裡強烈的厭惡這個工具。同時他也批判 Subversion 這個計畫是他看過最沒有意義的,因為 Subversion 從各方面試著去改善 CVS 的一些技術上的缺點,卻無法根本的解決一些基本使用限制。具體來說 Subversion 改善的創建分支的成本 (意思是相對 CVS 所利用的硬碟、計算資源比較少),但是卻沒辦法解決合併分支的需求,任何使用過 Subversion 合併分支的人都知道那是如何痛苦的折磨。而許多高度開發中的專案,都時常需要為不同的新功能開分支、合併,Subversion 解決了開分支的成本,卻沒有考慮到合併的人工成本。如此讓 Subversion 變成一個沒有未來的軟體計畫。
因此,基於過去在 BitKeeper 上得使用經驗,Linus 設計了新的 Git, 並將效能視為主要的需求。當然分散式的設計也是最重要的概念之一,Linus 提到幾個觀點,討論如下。
第一個是分散式的概念,解決了政治紛爭。所謂政治紛爭指 commit/checkout/create branch 的權利,傳統中央集權式開發模式,你若想要創建一個新的分支,或者進行一些實驗性的開發,通常必須獲得主開發者授予 提交者 (commitor) 的權限,意指你是受到信任的一份子,有權限可以自行修改軟體程式碼,被授權進行一些嘗試。(唐鳳的人人皆為提交者開發模式為例外)
這種模式,很自然的排擠了在所謂信任圈 (core developers) 外的人。對,你依然可以在中央控管的機制下嘗試,你依然可以透過 patch 提交你想要做的更動。但是工具本身的限制,直接的限縮了自由發展的可能性。舉例來說,你相對不容易組成一個工作小組 (Task Group),因為分享程式碼的變動並不容易,你可能必須建立另外一個獨立的程式碼管理系統給這個工作小組使用。而不像分散式的管理工具如 Git/Mercurial 開發者間可以透過數種管道接取/同步雙方的進度。
或者中央集權工具的另外一個根本上的問題是 - 它阻礙了開發者的實驗精神。
簡單講,就是開發者礙於每次提交 (commit),都可能因為程式碼的不相容性,造成其他人必須停下來彙整變更,影響到其他人的工作進度的後果,因此每次提交/儲存都會有所疑慮。因此很 容易就演變成開發者埋頭苦幹,直到最後一刻才一口氣提交上線,結果造成的不相容與衝擊更大,反而造成最後的工作成果難以融合。
在分散式開發工具的輔助下,你可以隨意的開立新分支,自行修改、測試、同步、實驗,這些在本地的提交除了完全不會影響到其他人外,同時你也可以輕易的匯出成特定格式 (patches),讓他人更容易的整合。這大幅改善了協同開發模式的磨合問題。
Git 是以分散式開發模式為根本,自然可以融合於相對單純的中央集權 (cvs/svn) 的權利結構。Linus 在演講中也提出了一個我認為很值得討論的觀點,即是應用於 Linux kernel 開發的多層次分散權利結構。Linus 提了一個重點,基本上開發社群中有一種信任關係 (Web of trust),像 Linux Kernel 這樣的龐大計畫,每個版本參與的開發者大約千人。 實際上主要開發者如 Linus 不可能認識這麼多人,很自然的,他只能信任最熟識的幾個人,他指知道幾個人的智商與能力都是足以信賴的,於是他只需要仰賴這些人的成果。而其他人在於自己 的信賴圈內,找到其他可以仰賴的人,於是利用這樣的信賴機制來擴展成網狀的開發社群。
在實務上,社群中也會演化出幾個角色,像是司令官 (dictator)、副官 (lieutenants)、開發者。幾位副官只要專注在他們熟悉的領域,整合開發者的成果,並提交給司令官做最後的整合決策。這麼一來,各種不同的專業 領域都可以交給最熟悉的開發人員管理,而開發不會被限制、停頓在某個角色身上,相對而言是一個比較具有效率的開發社群結構。且分散式開發,也讓不同的開發 者得以有權利與自由自行發展,不受限於官僚機制的限制。
上述為演講內容的一些提要。
Web of trust 是我相當認同的一個概念,任何所謂社群中,都會自然的因為信賴關係存在更小的團體,有人誤解這是一種分裂,但是我認為這是一種演化,不該消弭小圈圈的存 在,反而應該鼓勵小團體的成立,自行交流、合作,才有機會產生或再演化出更大、更有力量、更健康的社群。(應該有什麼什麼政治學、社會學的理論在講這件事 情吧 ?)
另外也推薦一個網站,是即將被國家綁架去服役的 kanru 翻譯的「為什麼 Git 比 X 棒」(Why Git is Better than X)。這個網站簡約的說明了 git 與其他程式碼控制軟體的比較,可以讓你比較容易了解各種軟體間的差異細節。
另外 為什麼 Git 比 X 棒 這個網站中介紹的 github 服務,我個人相當欣賞,它基本上提供了 Git 的 hosting 服務,但同時也包含了更多 Web 2.0 的概念,是所謂 “Social coding hosting”,基本的功能除了提供 Git 外,像一般的社交網站一樣,你可以追蹤別人的狀態,別的網站你追蹤的是朋友發出來的訊息,這裡你追蹤的是朋友寫出來的程式碼,而且你可以直接在線上「複 製」(branching) 別人的工作成果,也提供了相當美觀的介面,讓你看到程式碼更動的網路關聯圖,相當有趣。剛開始使用 Git 時,可以試試這個網站。
若想學習 Git, 請參考 Learning git 一文的連結。
一小時內搞懂 Git
此文轉自:http://people.debian.org.tw/~chihchun/2009/01/05/understand-git-in-one-hour/
我已經在 Learning git 中提到 Scott Chacon 的 GitCasts 網站,網站中包含相當多的操作示範影片。但是其中有一則在原本的文章沒提到的是 Scoot 在 RailsConf 2008 對 Git 做了一個相當精彩的演講,若你原本有使用其他版本控制系統的經驗,花一個小時聽完 Scott 的介紹應該是最有效率的方法。
這場演講中,Scott 廣泛的介紹 Git 的設計理念與使用方法,解釋了 Git 所使用的 DAG Storage 與 SVN 所用的 Delta Stroage 的內涵差異,深入說明 Git 所使用的 Object Model,並解釋那些特別容易令人困惑的 index, remote/local branches 的概念,甚至幫你說明了最重要的幾個 Git 指令的使用方式。專心聽完,真的可以馬上學會喔。
(請按播放視窗的圖示將影像全螢幕較適合閱讀。)
簡報可於 SlideShare 取得。聽完還意猶未盡的話,請深入閱讀 Git Community Book 吧。
對了,Perl 社群最近也開始使用 Git 來作為版本控制系統了。
January 5th, 2009 at 8:00 am | Comments & Trackbacks (1) | Permalink
Thursday, January 08, 2009
詩篇 第 一四三 章
143:0 大衛的詩。
143:1 耶和華阿,求你聽我的禱告,側耳聽我的懇求,憑你的信實和公義應允我;
143:2 求你不要傳喚你的僕人去受審,因為在你面前,凡活著的人沒有一個是義的。
143:3 原來仇敵逼迫我,將我的命壓倒在地,使我住在幽暗之處,像死了許久的人一樣。
143:4 所以,我的靈在我裏面發昏;我的心在我裏面驚懼。
143:5 我追想古時之日,默念你的一切作為,默想你手的工作。
143:6 我向你伸開雙手禱告,我的魂渴想你,如乾旱之地盼雨一樣。〔細拉〕
143:7 耶和華阿,求你速速應允我;我的靈耗盡。不要向我掩面,免得我像那些下坑的人一樣。
143:8 求你使我清晨得聽你的慈愛,因我信靠你。求你使我知道當行的道路,因我的魂仰望你。
143:9 耶和華阿,求你救我脫離我的仇敵;我逃往你那裏避難。
143:10 求你指教我遵行你的旨意,因你是我的神;願你至善的靈引我到平坦之地。
143:11 耶和華阿,求你為你的名將我救活;憑你的公義,將我從患難中領出來;
143:12 憑你的慈愛剪除我的仇敵,滅絕一切欺壓我的人,因我是你的僕人。
143:1 耶和華阿,求你聽我的禱告,側耳聽我的懇求,憑你的信實和公義應允我;
143:2 求你不要傳喚你的僕人去受審,因為在你面前,凡活著的人沒有一個是義的。
143:3 原來仇敵逼迫我,將我的命壓倒在地,使我住在幽暗之處,像死了許久的人一樣。
143:4 所以,我的靈在我裏面發昏;我的心在我裏面驚懼。
143:5 我追想古時之日,默念你的一切作為,默想你手的工作。
143:6 我向你伸開雙手禱告,我的魂渴想你,如乾旱之地盼雨一樣。〔細拉〕
143:7 耶和華阿,求你速速應允我;我的靈耗盡。不要向我掩面,免得我像那些下坑的人一樣。
143:8 求你使我清晨得聽你的慈愛,因我信靠你。求你使我知道當行的道路,因我的魂仰望你。
143:9 耶和華阿,求你救我脫離我的仇敵;我逃往你那裏避難。
143:10 求你指教我遵行你的旨意,因你是我的神;願你至善的靈引我到平坦之地。
143:11 耶和華阿,求你為你的名將我救活;憑你的公義,將我從患難中領出來;
143:12 憑你的慈愛剪除我的仇敵,滅絕一切欺壓我的人,因我是你的僕人。
Wednesday, January 07, 2009
轉帳非IE不可?WebATM不必再受限!
http://tw.news.yahoo.com/article/url/d/a/090107/52/1ckos.html
你曾碰過使用WebATM服務,卻因為網路瀏覽器並非微軟IE而失敗嗎?現在這樣的情況將可獲得改善。由於國內民眾使用其他網路瀏覽器的比例越來越高,玉山銀行首創先例,將旗下WebATM擴大支援Firefox、GoogleChrome、Opera等瀏覽器,讓民眾從事網路金融交易更為方便。
...
這次擴大WebATM服務範圍,玉山銀行將提供支援Firefox、GoogleChrome、Opera等瀏覽器的軟體,民眾只要上網下載安裝驅動程式後,就能省略掉切換瀏覽器,才能使用WebATM的麻煩。
你曾碰過使用WebATM服務,卻因為網路瀏覽器並非微軟IE而失敗嗎?現在這樣的情況將可獲得改善。由於國內民眾使用其他網路瀏覽器的比例越來越高,玉山銀行首創先例,將旗下WebATM擴大支援Firefox、GoogleChrome、Opera等瀏覽器,讓民眾從事網路金融交易更為方便。
...
這次擴大WebATM服務範圍,玉山銀行將提供支援Firefox、GoogleChrome、Opera等瀏覽器的軟體,民眾只要上網下載安裝驅動程式後,就能省略掉切換瀏覽器,才能使用WebATM的麻煩。
Subscribe to:
Comments (Atom)