https://medium.com/fcamels-notes/%E5%BE%9E%E7%A1%AC%E9%AB%94%E8%A7%80%E9%BB%9E%E4%BA%86%E8%A7%A3-memry-barrier-%E7%9A%84%E5%AF%A6%E4%BD%9C%E5%92%8C%E6%95%88%E6%9E%9C-416ff0a64fc1
之前從軟體的角度寫過 memory barrier 的介紹。《Memory Barriers: a Hardware View for Software Hackers》則是從硬體的角度了解硬體設計者的需求,以及 read/write memory barrier 如何運作。我只有讀完前五章,後面用我理解的方式摘要這篇文章。本文的圖示都是從該篇文章取出來的。


CPU 速度很快,main memory 讀寫速度很慢,所以要加上 cache 減少讀寫 memory 的次數,從《Latency Numbers Every Programmer Should Know 》得知存取 memory 的時間是 100 ns, L1 cache 是 0.5 ns,兩者差了 200 倍。
使用 cache 的時候,要確保各 CPU 有看到「一致的資料」 (注意重點放在 CPU 之間,不是 cache 和 memory 保持同步,這點細微的差異會影響到架構設計)。維護這點的協定統稱為 cache-coherence protocol。其中,MESI protocol 是一個基本版,從 MESI protocol 可以了解 CPU 之間如何維持看到一致的資料。
MESI Protocol
這篇文章有介紹 MESI protocol,不過個人覺得 Wikipedia 的介紹比較清楚一點,可以交互參照:
The letters in the acronym MESI represent four exclusive states that a cache line can be marked with (encoded using two additional bits):Modified(M): The cache line is present only in the current cache, and is dirty — it has been modified(M state) from the value in main memory. The cache is required to write the data back to main memory at some time in the future, before permitting any other read of the (no longer valid) main memory state. The write-back changes the line to the Shared state(S).Exclusive(E): The cache line is present only in the current cache, but is clean — it matches main memory. It may be changed to the Shared state at any time, in response to a read request. Alternatively, it may be changed to the Modified state when writing to it.Shared(S): Indicates that this cache line may be stored in other caches of the machine and is clean — it matches the main memory. The line may be discarded (changed to the Invalid state) at any time.Invalid(I): Indicates that this cache line is invalid (unused).
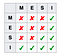

簡述一下四個狀態意思:
- Modified (M): 只有該 cache line 裡有最新資料,比 main memory 裡的資料還新
- Exclusive (E): 只有該 cache line 裡有最新資料,不過和 main memory 一致
- Shared (S): 有兩個以上的 cache lines 有最新資料,和 main memory 一致
- Invalid (I): cache line 內的資料已過時,不可使用
透過 MESI protocol,任何一個 CPU 要寫入資料前,都要先確保其它 CPU 已 invalid 同一位置的 cache 後 (希望寫入的 CPU 廣播 invalidate,其它 CPU 回 invalidate ack), 才能寫資料到自己的 cache,並在稍後補寫回 memory。
這個設計確保資料的一致性,不用擔心同一時間同一個位置的資料會有不同的值,但是代價是寫入 cache 的速度會有點慢,讓 CPU 閒置。


假設 CPU 0 打算寫入資料到位置 X,CPU 1 的 cache 有 X 的值。慢的原因如下:
- CPU 0 要等 CPU 1 回 invalidate ack。
- CPU 1 的 cache 可能太忙而拖慢了回覆時間 (比方同時從 cache 大量的讀寫資料,或是短時間收到大量 invalidate ack)。
Store Buffer 和 Invalidate Queue
針對上述問題,以下的方法可以縮短 CPU 0 閒置時間:
- CPU 0 不等 invalidate ack:先寫入 store buffer,然後繼續作事。之後收到 invalidate ack 再更新 cache 的狀態。因為最新的資料可能存在 store buffer,CPU 讀資料的順序變成 store buffer → cache → memory。
- CPU 1 立即回 invalidate ack:收到 invalidate 時,記錄到 invalidate queue 裡,先回 invalidate ack,稍後再處理 invalidate。
因為 store buffer 很小,store buffer 滿的時候,CPU 0 還是得等 invalidate ack,所以加上 invalidate queue,雙管齊下減少 CPU 0 等待時間。
擴展後的 cache 架構如下:


因為多了 store buffer 和 invalidate queue,cache 之間的資料就沒有完全一致了,該篇文章有詳細說明會產生問題的狀況,推薦一讀。這裡用我的方式簡述大概情況。
store buffer 的問題與 write barrier
int a = b = 0; void foo(void) { a = 1; b = 1; }void bar(void) { while (b == 0) continue; assert(a == 1); }
考慮 CPU 0 執行 foo(), CPU 1 執行 bar()。假設 cache 的狀態如下:
a b
------------------------
CPU 0: Shared Modified
CPU 1: Shared Invalid
CPU 0 步驟如下:
- 寫入 a 的值 (=1) 到 store buffer (但 cache 裡仍是 0)
- 廣播 “invalidate a”
- 改 b 的值。因為 b 的狀態已是 Modified,cache 的值更新成 1
接著 CPU 1 從 CPU 0 的 cache 讀到 b = 1,繼續執行 assert()。從自己的 cache 裡取值 (=0)。然後收到 CPU 0 送來 “invalidate a” 的訊息,但已太遲了。
問題出在 store buffer 破壞了 cache coherence,資料不再是同一時間只有一份值。於是 CPU 需要提供 write memory barrier,讓軟體有機會避免這個問題。
write memory barrier 確保之前在 store buffer 裡的資料會先更新到 cache,然後才能寫入 barrier 之後的資料到 cache。假設我們在
foo() 的 a=1 和 b=1 之間插一個 write memory barrier。文中介紹的實作方式如下:- write memory barrier 先設 store buffer 裡的資料為 “marked” (即
a=1) - 寫入 b 的時候,因為發現 store buffer 裡有 marked 的欄位,所以即使 b 已處於 Modified,仍需寫入
b=1到 store buffer,不過狀態是 “unmarked” - 待收到 a 的 invalidate ack 後,cache 中 a 的狀態改為 Modified,然後先寫入有 marked 欄位的值到 cache,再寫入 unmarked 欄位的值到 cache。
這樣其它 CPU 就會依序看到 a、b 更新的值了。
invalidate queue 的問題和 read memory barrier
用同樣的程式為例,假設 CPU 1 的 cache 裡 a 處於 Shared。CPU 0 已更新 a、b 到它的 cache,CPU 1 的 invalidate queue 裡有 "invalidate a”,但還沒處理。
這時 CPU 1 依序讀 b、a 的值,會從 CPU 0 的 cache 讀到
b=1,然後從自己的 cache 讀到 a=0 (因為還沒 invalidate a)。所以需要 read memory barrier 確保先清空 invalidate queue 再繼續讀資料。
若在
assert(a==1) 之前插入 read memory barrier,執行順序變成這樣:- CPU 1 執行 read memory barrier 時會設 invalidate queue 裡的資料為 “marked”
- CPU 1 讀 cache 裡 a 的值時,發現 invalidate queue 裡有標記 a,於是會先執行 invalidate a 再繼續讀 a 的值
- 執行 invalidate a 後,就不會讀自己 cache 的值,而改從 CPU 0 的 cache 讀到最新的值,達到「依序讀 b、a 的值」的效果。
結論
硬體為了減少讀寫 memory 而有 cache。有 cache 就要確保 cache 之間的資料一致 (同一時間同一位置只有一個值)。但確保 cache 資料完全一致容易讓 CPU 閒置,於是有了 store buffer 和 invalidate queue 降少 CPU 閒置。代價是只保證 CPU 自己會讀到自己寫入的最新資料,但其它 CPU 不一定。
為了讓其它 CPU 有需要的時候也能讀到最新的資料,針對 store buffer 和 invalidate queue 的副作用設計了 write/read memory barrier。於是寫軟體的人在需要的時候可以用 memory barrier 確保關鍵的資料有依正確的順序更新 (沒保證更新的時間)。CPU 在多數情況下仍能避免閒置。
到此可以了解為什麼這兩種操作合在一起比較符合 CPU 架構:
- 一個 thread 「先 write X 後執行 write memory barrier」
- 另一個 thread 「先執行 read memory barrier 後 read X」
兩者合起來構成 happens-before relation。由此可以理解 Sequential-consistent 和硬體的運作方式差太多,會太常讓多個 CPU 閒置,無法發揮多 CPU 的效能。